
爬虫

爬虫
小楼夜听雨基础
获取网页内容
HTTP协议(超文本传输协议)
HTTP是一种客户端和服务端之间的请求-响应协议
客户端通过发送协议内容给服务端,服务端进行响应
例如:在浏览器访问网站,就是给服务器发送请求,等待服务器响应发送回网页内容
HTTP请求

请求行:方法 资源路径[?查询参数1&查询参数2..] 协议版本
GET方法
主要用于获取数据
例如:获取网站页面
POST方法
主要用于创建数据
例如:将用户注册信息等放到请求主体发给服务器
请求头:包含给服务器的信息
host:主机域名(域名+资源路径=完整的网址)
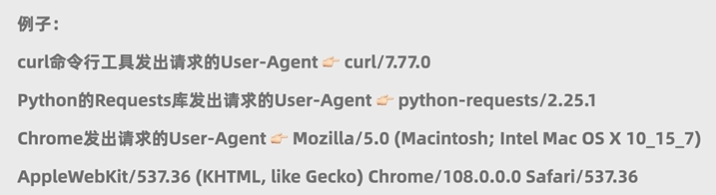
User-Agent:告知服务器客户端的一些信息

Accept:告知服务器客户端想要接收的响应是什么类型的,多个可用逗号隔开

请求体:可以放客户端给服务器的任意数据(一般get方法用不上)
HTTP响应

状态行:协议版本 状态码 状态信息

响应头:包含一些告知客户端的信息
- date:生成响应的时间
- content-type:返回内容的类型和解码格式
响应体:服务器响应客户端的内容
requests模块
requests模块是Python用于构建和发送HTTP请求的第三方库
下载模块
1 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests |
导入模块并发送请求
1 | import requests |
注意:get方法里面需要完整的URL
判断响应是否成功
1 | import requests |
将爬虫程序伪装成正常浏览器
在我们使用浏览器发送请求的时候,会自动发送User-Agent浏览器的版本等信息
使用代码程序发送的话,则不会,因此我们需要自己定义
1 | import requests |
User-Agent可以去任意一个网站,检查->网络->Fetch/XHR,刷新一下即可获取浏览器发送的所有HTTP请求,打开任意一个,翻到最下面获取User-Agent
解析网站内容
Python中,有一个bs4的模块可以解析网站内容
下载
1 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4 |
引入
1 | from bs4 import BeautifulSoup |
传入构造函数,创建实例
1 | A =requests.get("https://books.toscrape.com/",headers =head).text |
由于BeautifulSoup可以解析很多内容,所以除了传入html之外,还需要传入html.parser表示解析html
BeautifulSoup会把html解析成树状结构
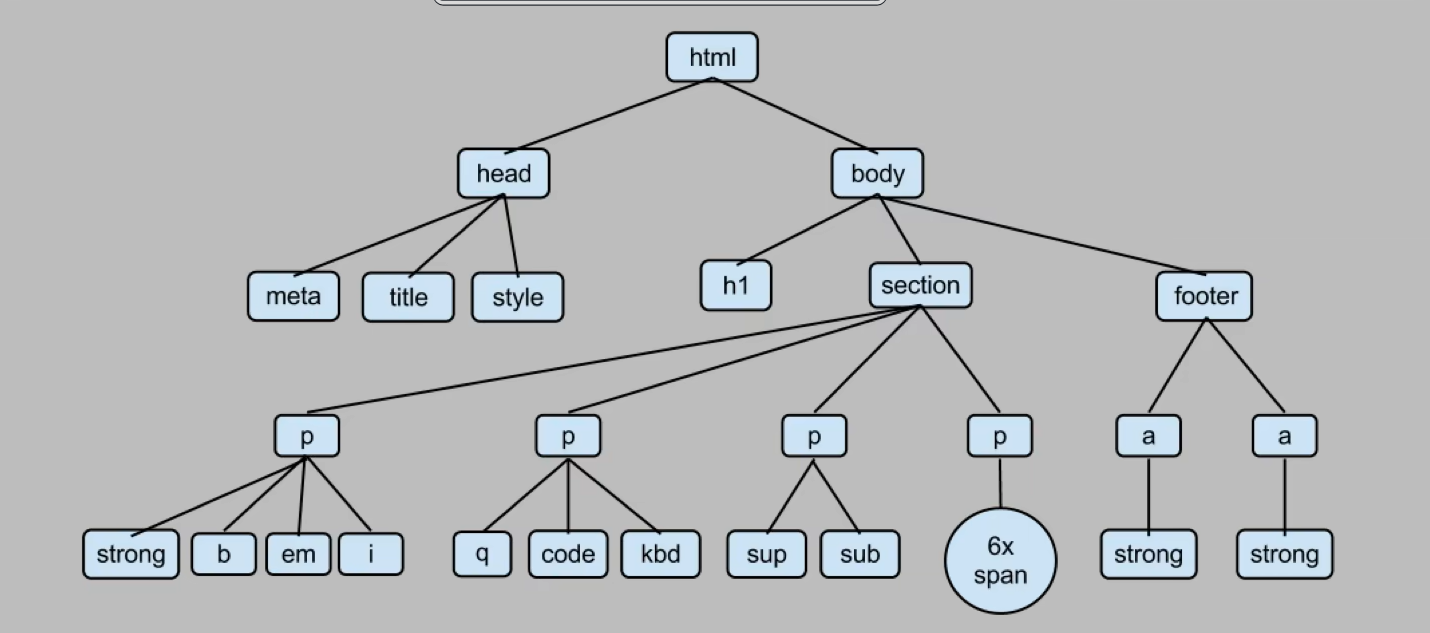
获取我们需要的内容
通过上面的实例对象,我们可以通过方法可以获取我们需要的内容
1 | import requests |
find_all(标签,筛选内容)方法可以获取全部筛选内容的标签
find(标签,筛选内容)方法可以获取第一个筛选内容的标签
.string可以只获取标签的包围的内容
多重筛选
如果我们遇到想要的内容的标签属性不一样,那么我们可以使用多重筛选标签的方式进行筛选
1 | import requests |
案例:
获取B站推荐页的所有视频标题
1 | import requests |
进阶
渲染
服务器渲染:
在服务器那边直接把数据和html整合在一起,统一返回给浏览器,在页面源代码中能看到数据
客户端渲染:
第一次请求只要一个html骨架,第二次请求拿到数据, 进行数据展示,在页面源代码中看不到数据
要熟练使用浏览器抓包工具
发送post请求
发送post请求时,发送的数据必须放在字典中,使用data进行传递
1 | response = requests.post(login_url, data=login_data) |
跳过安全证书认证
有些网站会要求认证安全证书,通过verify=False可以无视风险
1 | response = requests.post(login_url, data=login_data,verify=False) |
定向获取html
如果我们只需要获取html的一小段,可以利用re正则表达式筛选惰性匹配
1 | 我是大帅哥,我非常帅,大帅哥是我 |
获取图片
找到图片的链接src
1 | A = requests.get(src) |
绝对路径查找html内容
下载lxml包
1 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml |
导入
1 | from lxml import etree |
使用
1 | tree= etree.HTML(A.text) #获取了网页html的A |
路径使用方法
1 | /html #/表示层级关系,第一个/表示根节点 |










