
Python

Python
小楼夜听雨导论
一共会分为4个板块
入门
- 数据类型
- 语法
- 容器
- 函数
- 文件交互
- 异常和包
类和对象
- 类的基础
- 魔术方法
- 继承复写
- 类型注解
- 多态
- 数据库
pyspark大规模分布式计算
- 构建对象
- 数据输入
- 数据计算
- 数据输出
进阶
- 闭包
- 装饰器
- 设计模式
- 多线程编程
- 网络编程
- 正则表达式
- 递归
Python入门
字面量
字面量就是值,包括整数,浮点数,字符串等
注释
单行:#
多行:””” “””
变量
不同于C语言,在Python中,变量不需要定义类型,直接定义变量名并赋值即可
注意:在Python中,语句之间不用使用分号隔开
1 | money = 10 |
数据类型
虽然在Python中定义变量不用定义数据类型,但是会根据输入的值自动定义数据类型,是一种弱数据类型的编程语言
我们可以通过**type()**函数获取变量的数据类型并返回
1 | money = 1 |
数据类型转化
在Python中,可以通过对应函数将数据类型进行转化,如:
1 | str(111) #将111转化成字符串 |
标识符
同其它编程语言一样,Python在给变量,方法,函数等命名的时候
不可以使用
- 1.数字开头
- 2.关键字
不建议使用中文
运算符
| 运算符 | 作用 | 效果 |
|---|---|---|
| // | 取整除 | 9//4 = 2 |
| % | 取余 | 9%2 =1 |
| ** | 指数 | 2**3 =8 |
| += | 累加 | C=0; C += 2 C=2 |
| //= | 累整除 | C=10; C//=2 C=5 |
| %= | 累取余 | C=10; C%=2 C=0 |
| **= | 累指数 | C=10; C//=2 C=100 |
| 累~ | 就是将值运算之后再赋给本身 |
字符串
定义方法:
- 使用单引号
- 使用双引号
- 使用三对双引号(必须有变量,不然就是注释)
1 | '111' |
在字符串内使用单引号或者双引号:
- 嵌套法
- 使用转义字符 \
1 | " '1111' " #会输出'1111' |
字符串拼接
通过+号可以将字符串拼接到一起
1 | print ("sdsa"+"sdada") |
字符串格式化
通过占位符格式将字符串和其它数据类型拼接到一起
%表示占位
- s表示将数据变成字符串代替s
- d表示将数据变成整数代替d
- f表示将数据变成浮点数代替f
数字精度控制:
m.n f/d:m为整数长度,n为小数长度,整数少于m时m生效
1 | print ("名字是:%s先生 ,电话是 %s"%("张三",123456788)) |
快速格式化
通过f{变量/表达式}格式
1 | A=1,B=2 |
输入语句
input(“提前输出的内容”)
1 | A = input("你是?"); |
布尔类型
在Python中,布尔类型不用定义,直接将布尔值赋值给变量即可
1 | A = "123" == "123" |
if语句
在Python中,通过缩进来判断语句的级别,而不使用;
语法: if 判断语句 :真时执行语句 else :假时执行语句
1 | A = 30 |
while循环
while 条件 : 循环语句
break可跳出循环
1 | while 1: |
for循环
和C语言不同,Python的for循环是将序列的每一项数据提取进行处理,序列包括:字符串,列表,元组deng
for 临时变量 in 序列 : 执行语句
注意:用于Python靠缩进来进行语句分级,所以x在for循环外依然可以被使用,但是并不规范
1 | A = "123456" |
range语句
用来生成序列,搭配for循环使用
- range(10):生成0-9
- range(5,11):生成5-10
- range(1,10,2):生成1,3,5,7,9
1 | for X in range(10): |
练习:乘法表
1 | for a in range(1,10): |
print()可以作为回车符使用
\t 表示空一格
end=’ ‘表示不用换行
break和continue
break表示结束
continue表示跳过
1 | for i in range(10): |
函数
定义:def 函数名 (形参):函数体 返回值
1 | def AAA (a): |
注意:
- 如果不返回值的话,会返回None,表示空,并表示什么都不返回
- None = flase
- not None = true
拓展:
返回多个值 可以 return 1,2,并使用两个变量接收
1 | def AAA (): |
传参方式:
在Python中,除了常用的位置传参外还可以通过关键字,缺省参数(默认),不定长参数(*位置和**关键字)
注意:位置不定长参数传入为元组,关键字不定长参数以键值对传入为字典,这两种方式都没有规定传入参数的数量
1 | def AAA (a,b,c=3):#位置,关键字,缺省参数 |
函数逻辑作为参数
在一些时候,函数里面的数据是固定的,但是需要不同的处理逻辑,因此我们可以把函数作为参数传入另一个参数,实际上是传入了函数的逻辑算法
1 | def A(a,b): |
匿名函数:
在一些只需要使用一次的函数,我们可以定义为匿名函数,匿名函数默认返回值,并且只可以使用一次
lambda 参数 :函数体(只一行)
1 | def A(a,b): |
global转化为全局变量
在python中,无论是否传入形参,函数里面的变量都为形参,不影响实参,也就是局部变量不影响全局变量,
global相当于指针函数,在函数内的形参变量前面添加global,则可以影响到实参(全局变量)
1 | A=100 |
数据容器
序列-列表(类似数组)
定义
列表名 =[元素,元素…] [“assda”,112233,True,]
列表可以储存不同的数据类型,可以嵌套
通过下标可以索引到对应的数据,下标从0开始
反向索引:从后面开始,开始下标为-1,然后-2
注意:字符串表示也是一种列表可以使用下标索引对应字符
1 | A = ["assda",112233,True] |
列表的方法
查询元素的下标:列表.index(元素) 没有则报错
修改:列表[下标] = 新值
插入:列表[下标, 值] 下标原来的数据自动往后
追加元素:列表.append(元素),在最后面追加元素
追加数据容器(批量):列表.expend(容器),在最后面追加列表等数据容器的值,不是嵌套
删除:
- del 列表[下标] 直接删除,会自动补位
- 列表.pop(下标) 返回元素并删除
- 列表.remove(元素) 删除第一个匹配的元素
清空:列表.clear()
统计:
- 列表.count(元素) 统计指定元素的数量
- len(列表) 统计全部元素的数量
列表案例
已知列表[23,24,25,26]
要求追加27和[28,29],取出第一个和最后一个元素
遍历该列表
1 | A = [23,24,25,26] |
序列-元组
在python中,元组就是只读的列表,一旦定义就不可修改
定义:
元组名 = (元素,元素,元素…)
空元组: 元组名= () 或者 元组名= tuple()
元组可以嵌套,如:A =((1,2,3),(4,5,6))
通过下标可以索引到对应的数据,下标从0开始
注意:如果元组中只有一个元素,需要在元素后面加逗号,不然就是字符串
元组的方法
查询元素的下标:元组.index(元素) 没有则报错
统计:
- 元组.count(元素) 统计指定元素的数量
- len(元组) 统计全部元素的数量
特殊情况:如果元组里面嵌套了列表,则可以修改列表里面的内容
1 | A =((1,2,3),[4,5,6]) |
序列-字符串
字符串也是数据容器,同样适用数据容器的规则,同时并不可修改,空格也算字符
方法:
查询元素的起始下标:字符串名.index(“元素”) 没有则报错
替换元素:字符串名.replace(”要替换的元素”,”新的元素”)替换之后需要新的变量接收,本身并不会改变
按照指定的元素把字符串进行切割成列表:字符串名.split(“指定元素”) 切割之后需要新的变量接收,本身并不会改变
去除前后的指定元素:字符串名.strip(“指定元素”) 或者如果没有参数,字符串名.strip() 去除前后的空格和换行符
统计:
- 字符串名.count(元素) 统计指定元素的数量
- len(字符串名) 统计全部元素的数量
1 | A ="I IS ABC" |
序列的切片
在python中,可以对序列进行切片截取
语法:序列名[起始下标:结束下标:步长] [起始下标:结束下标]
步长:截取的距离,如果是1(可不写),则一个一个取,如果是2,则间隔1个再取
起始下标为空表示从头开始,结束下标为空表示到结尾再结束,步长为空表示没有间隔
注意:步长为负表示反向取,起始下标,结束下标也要为负
1 | A ="I IS ABC" |
切片案例
字符串987654321,获取456
1 | A ="987654321" |
集合
和序列不同,集合是无序的(不支持下标索引访问),不可重复的
定义:集合名={元素,元素,…} 空集合 = set()
修改方法:
添加:集合名.add(元素)
移除:集合名.remove(元素)
随机取出一个元素,并移除:集合名.pop()
清空:集合名.clear()
取差集(不同):C=集合A.difference(集合B) 取A中和B的不同并返回,不影响A和B
消除交集(相同):集合A.difference_update(B) 删除A中和B相同的元素,不影响B
合并:C=集合A.unior(B) 合并A和B并返回,不影响A和B
统计元素个数:len(集合)
遍历:for i in 集合:prant(i)
集合案例—信息去重
列表[1,2,3,4,5,6,1,2,3,4,5,6,7]
1 | A =[1,2,3,4,5,6,1,2,3,4,5,6,7] |
字典
字典是键值对的集合,可以通过键去检索值(不可下标索引)
定义:
字典名 = {key1:值,key2:值….}
空字典:
- 字典名={}
- 字典名=dict()
注意:key不可重复,如果重复,则值取最后一个key的值
使用:
1 | A= {"ab":66,"bc":77,"bc":88} |
关于嵌套:key不可以为字典,值可以为任何类型
方法:
新增/修改:字典名[key]=值 如果没有这个key,则新增
删除:字典名.pop(key)
清空:字典名.clear()
获取全部key:字典名.keys(),遍历时,也可以直接in字典名,也是遍历所有key
统计元素(键值对)数量:len(字典名)
嵌套字典案例—学生的成绩
查看张三的语文成绩
张三的语文成绩修改为99
删除张三的英语,添加日语成绩92
查看所有人的成绩
| 语文 | 数学 | 英语 | |
|---|---|---|---|
| 张三 | 100 | 88 | 77 |
| 李四 | 75 | 75 | 75 |
| 王五 | 0 | 36 | 100 |
1 | A= {"张三":{"语文":100,"数学":88,"英语":77},"李四":{"语文":75,"数学":75,"英语":75},"王五":{"语文":0,"数学":36,"英语":100}} |
容器的通用方法
len(容器):获取元素数量
max(容器):获取元素最大值 通过对比每一位字符的ASCII码表比较,字符串比字符,字典比key
min(容器):获取元素最小值
文件交互
计算机通过编码将信息转化为二进制,我们日常使用编码格式为 UTF-8
打开文件
通过f = open(“文件地址名称”,“打开方式”,encoding=”编码格式”)创建一个对象
| 打开方式 | 意思 | 效果 |
|---|---|---|
| r | 只读(默认) | 打开文件之后只可读,指针在最前 |
| w | 只写 | 文件存在则删除重新写入,不存在则创造文件写入 |
| a | 追加 | 文件存在则在最后追加写入,不存在则创造文件写入 |
方法
只读取指针后,封装成字符串:f.read() 如果只读取指针后对应字节f.read(10)
读取指针后全部行,并封装到列表中:f.readlines()
读取指针后一行,并封装到列表中:f.readlines()
遍历每一行:for i in f:print(i)
关闭文件:f.close() 包含写入硬盘f.flush()
文件自动关闭语法:with open(“文件地址名称”,“打开方式”,encoding=”编码格式”) as f:操作
写入内存:f.write(“?????”)
写入硬盘:f.flush()
文件睡眠:f.sleep(50) 文件睡眠50秒,期间文件会在运行无法外部操作
文件交互案例
1 | 张三 100 花费 |
读取文件,将测试删除,然后备份
1 | f = open("123.txt","r",encoding="UTF-8") |
异常处理
异常捕获
在Python中,如果程序出现bug,那么程序就会停止运行,如果我们可以捕获bug,并给出处理方案,那么程序就不会停止运行
通过 try:可能出现bug的语句 except:补救方案可以实现对应补救
1 | try: |
捕获指定异常:我们可以只捕获指定的异常,并提供解决方案
try:可能出现bug的语句 except (指定异常1,2) as i:补救方案 i记录了异常信息
1 | try: |
捕获全部异常:我们可以捕获全部的异常,并提供解决方案
- try:可能出现bug的语句 except:补救方案
- try:可能出现bug的语句 except Exception as i:补救方案 是一种顶级异常捕获
没有捕获到异常:可以使用else继续执行代码
无论有没有异常都要执行:可以所用finally代码
1 | try: |
异常的传递性
如果异常发生在函数调用的时候,那么异常可以在调用的时候被捕获
1 | def a(): |
模块
模块是工具包,库函数,需要导入才可以使用
方法:
import 模块名
导入全部功能,需要以 模块名.功能名方式使用
from 模块名 import 指定模块里的类函数变量等
只能使用指定的功能,需要以 模块名.功能的方式使用
from 模块名 import *
导入全部功能。可以直接以功能名使用
import 模块名 as 别名
导入全部功能,需要以 别名.功能的方式使用
from 模块名 import 功能名 as 别名
只能使用指定的功能,需要以 别名的方式使用
自定义模块
新建py文件,在py里面编写内容,再导入即可,模块名就是文件名
注意:在自定义模块的时候,用于在导入的时候会执行一次模块的文件,如果模块里面有调用函数,则会被执行,我们可以使用main然后快捷输入
1 | if __name__ == '__main__': |
文件在执行的时候会判断是否以主函数执行,如果是的话,就执行,如果是被导入的话,就是在别的文件被调用,自定义模块的__name__就不是'__main__',就不会被执行
以*号导入全部的时候,也可以只导入我们准备的内容,可以通过在模块中添加
1 | __all__ = [ '函数1'] |
那么,我们使用*导入的时候就只能使用函数1
包
在Python中,模块就相当于mod,包就是模组,包用于集中管理模组,避免麻烦和遗漏
创建包:
创建一个Python package文件夹(文件自动包含init.py文件管理模块)
将模块都放入文件夹
导入模块
- import 包.模块
- import 包.模块.功能
- from 包 import 模块
- from 包.模块 import 功能
通过from导入的,使用的时候不用通过.
安装第三方包
通过终端
pip install 包名
通过外网下载
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
通过国内清华大学镜像下载
数据可视化案例
JSON 模块
JSON是一种轻量的数据交互格式,可以将数据按照指定的方式封装保存(本质上是一个带有特殊格式的字符串)
功能:可以实现在各个语言中的数据交互,每个语言的数据容器不一样,如C++中的数组,Python中的字典(作为翻译官使用)
JSON的储存格式为:字典 或者 列表里面包含字典
1 | {"name":"张三","phone":12345678910} |
使用:
在Python中导入json模块
1 | import json |
将Python数据转化为json,通过json.dumps(数据)
1 | A ={"name":"张三","phone":12345678910} |
将json数据转化为Python,通过json.loads(数据)
1 | A = json.loads(A) |
pyecharts模块
pyecharts模块是百度提供的数据图形可视化模块
安装
1 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts |
制作成图表:
去除3个json前面和后面的错误
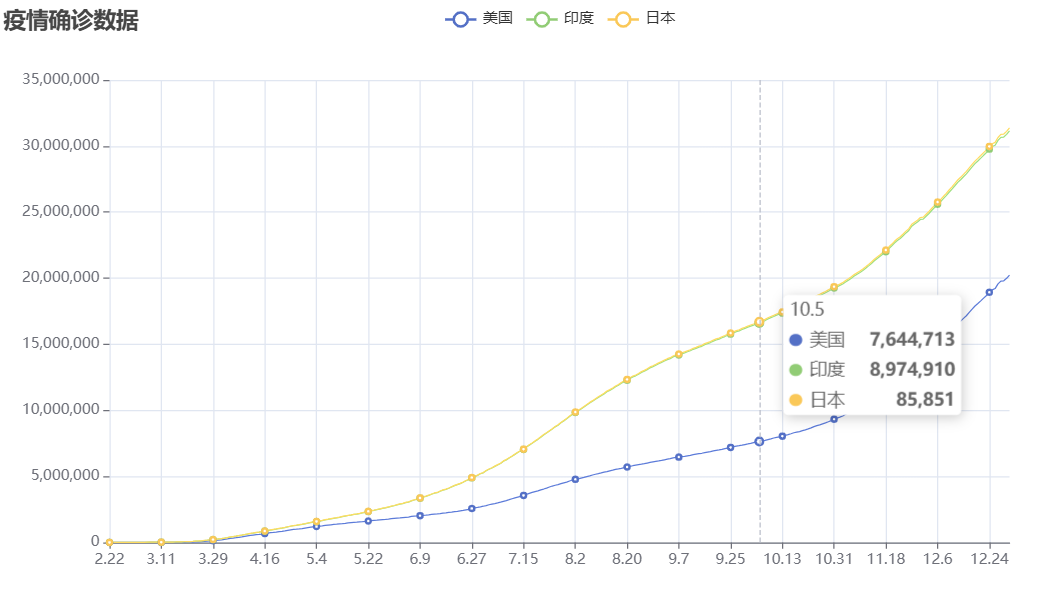
将2020年美国印度日本的疫情确诊数据制作成图表
1 | import json |
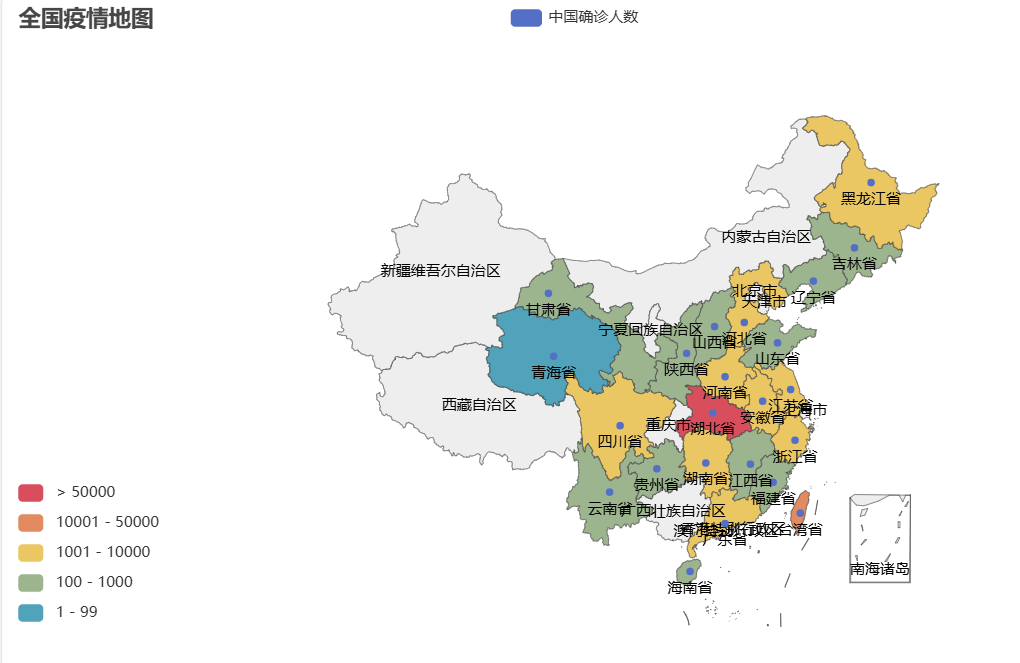
制作成地图:
1 | import json |
类和对象
在Python中,创建一个类和C一样,但是方法的定义不一样
self 相当于C中的this,表示类对象自己,用于在方法中访问自身的变量
1 | class 类名 : |
实例对象以及使用:
1 | 对象名 = 类名() |
构造方法(函数):
1 | def __init__(self,形参1.....): |
魔术方法
在Python中,在类中内置了很多方法,和构造函数一样,魔术方法的特征就是_ ?_
字符串方法 str
如果我们实例了一个对象,并且直接输出对象的时候,就会输出对象的地址
通过字符串方法,我们可以将对象转化成字符串输出
1 | class student: |
对象比较方法 lt 和 le
两个对象之间正常情况下是不能比较的,但是通过魔术方法可以,类似于C++中的运算符重载
如果没有定义魔术方法,则不能进行比较, ==则会比较地址,一定会输出false
1 | student1 = student("张三",12) |
私有变量和方法
定义私有属性可以防止对象使用,只能类内部使用
在变量或者方法名前面加__就可以
1 | class student : |
继承
通过继承,可以将父类的一些属性继承给子类
- 如果继承多个父类,父类中相同的变量方法名,则左边优先(父类名1)
- 如果对父类中的属性不满意,可以进行复写
- 如果复写之后还想要使用父类的属性,则可以通过调用实现:
- 父类名.成员变量
- 父类名.成员方法(self)
- super().成员变量
- super().成员方法()
1 | class 类名 父类名1: |
类型注解
在我们调用函数或者传参的时候,如果是Python自带的则会提示我们要输入什么类型,如果是我们自己定义的,则不会,因此我们可以进行注解
方法1:直接加
1 | 变量: |
方法2:在后面加上#type:类型,也可以具体
1 | a = [1,2,3] #type:list |
在函数中,形参和返回值的注解:
1 | 形参: |
混合类型注解:
如果传入的类型不止一种,可以使用Union:
1 | from typing import Union |
多态和抽象类
多态就是一个方法的多个状态,如果子类对父类的方法进行了复写,那么如果一个函数的参数是父类,那么也是可以传入子类作为形参,导致函数执行子类的方法
1 | class A: |
类案例
将2个月份的数据制作成图表
1 | import json |
数据库
可视化工具:DBeaver
创建表:create table 名称 (数据名称 数据类型)
1 | sql |
| 类型 | 指令 | 范围 |
|---|---|---|
| 整数 | TINYINT | -128到127 |
| 整数 | SMALLINT | -32768到32767 |
| 整数 | MEDIUMINT | -8388608到8388607 |
| 整数 | INT | -2147483648到2147483647 |
| 整数 | BIGINT | -9223372036854775808到9223372036854775807 |
| 小数 | DECIMAL() | 在存储时需要指定总位数和小数位数。示例:(10,2) |
| 字符串 | CHAR | 定长字符串,存储0到255个字符 |
| 字符串 | VARCHAR() | 变长字符串,可以存储0到65535个字符,示例:(100) |
| 字符串 | TEXT | 用于存储较长的文本数据,最大长度为65535个字符 |
| 日期 | DATE | 格式为YYYY-MM-DD。示例:“2022-05-15” |
| 时间 | TIME | 格式为HH:MM:SS。示例:“12:30:45” |
| 日期和时间 | DATETIME | 格式为YYYY-MM-DD HH:MM:SS。示例:“2022-05-15 12:30:45” |
| 日期和时间 | TIMESTAMP | 自动记录最后修改的日期和时间。示例:“2022-05-15 12:30:45” |
| 枚举 | ENUM() | 用于定义一组可能的值,只能选择其中的一个值。示例:ENUM(“Male”,“Female”),只能选择”Male”或”Female” |
| 集合 | SET() | 定义一组可能的值,可以选择其中的多个值。示例:SET(“Red”,“Green”,“Blue”),可以选择”Red”、“Green”和”Blue” |
| 布尔 | bool | 可以存储True或False |
上述数据类型都支持一些属性,如指定默认值、是否允许为空、是否自增等。例:
指定默认值:默认值属性用于在插入新行时为列指定一个默认值。示例:
age INT DEFAULT 18,默认将年龄设置为18。是否允许为空:允许为空属性用于确定该列是否可以为空。示例:
address VARCHAR(100) NULL,地址可以为空。是否自增:自增属性用于在每次插入新行时自动为列生成唯一的值。示例:
id INT AUTO_INCREMENT PRIMARY KEY,id将自动递增,作为主键。
显示表结构:desc 表名
1 | sql |
删除表:drop table 表名
1 | sql |
表结构修改:
数据表添加列:alter table 表名 add 列名 类型;
1 | sql |
数据表删除列:alter table 表名 drop 列名;
1 | sql |
数据列改名:alter table 表名 change column 原名 改名 类型
1 | sql |
数据列修改数据类型:alter table 表名 modify column 列名 改后类型
1 | sql |
修改表名:alter table 原名 rename to 改名
1 | sql |
插入数据项:insert into 表名(要添加的列名) value (对应的数据);(如果都添加可直接表名)
1 | sql |
删除数据项:delete from 表名 where 列名=?
1 | sql |
修改数据项:update 表名 set 修改的列名 =’1’ where 修改的对象 =’ ‘
1 | sql |
设置主键:
创建表时:
1
2sql
primary key (列名)现有的表:
1
2
3sql
ALTER TABLE 表名
ADD PRIMARY KEY (列名);
自增主键:
创建表时:
1
2
3sql
CREATE TABLE 表名 (
列名 类型 AUTO_INCREMENT PRIMARY KEY,);现有的表:
1
2
3sql
ALTER TABLE 表名
MODIFY 列名 类型 AUTO_INCREMENT PRIMARY KEY;
逻辑运算符(筛选)
筛选中间的值:
语法:select * from 表名 where 列名 between 最小值 and 最大值;
1 | sql |
作用和使用><是一样的
1 | sql |
筛选这一列为空的值:
语法:select * from 表名 where 列名 is null;
1 | sql |
筛选指定的值:
语法:select * from 表名 where 列名 in (值1,值2,…)
1 | plaintext |
筛选包含有元素的值
通配符:
- % 代表任意字符和数量
- _ 一个下划线代替一个字符
语法:select * from 表名 where 列名 like ‘通配符 特征 通配符’;
1 | sql |
分组聚合
筛选之后进行求和最大最小值等
语法:select 列名,聚合函数 from 表名 [ where 条件 ] group by 列名(被分组的列)
1 | select 年龄,sum(年龄) from 表名 group by 年龄 |
排序
对列进行排序
语法:正常查询的语法内容 order by 列 [函数]
1 | select 年龄 from 表名 where 年龄>20 order by 年龄 asc; |
查询条数
语法:正常查询的语法内容 limit n [,m]
1 | select 年龄 from 表名 where 年龄>20 order by 年龄 asc limit 5 展示5条 |
Python操控数据库
安装第三方库
1 | pip install pymysql |
连接数据库
1 | from pymysql import Connection |
执行修改语句
1 | #修改 |
执行查询语句
1 | #查询 |
spark
spark可以对海量数据进行大规模分布式计算
既可以在电脑计算,也可以在服务器集群进行分布式计算
安装myspark
1 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark |
构建执行环境入口对象
SparkContex是执行的类,构建其对象来执行spark的所有命令
1 | #导入包 |
数据输入
RDD(弹性分布式数据集):pyspark支持多种数据容器输入,在输入完成之后,都会得到一个RDD类的对象
数据储存在RDD内,我们可以通过RDD的方法对数据进行计算,返回值依然是RDD,因此可以进行多次计算
读取容器
通过SparkContext类对象的paralleize方法传入数据
1 | rdd = sc.parallelize(容器对象) |
注意:
- 字符串会被拆分成1个个字符储存到RDD
- 字典只有key会被储存到RDD
读取文件转RDD对象
通过SparkContext类对象的textFile方法传入数据
1 | RDD6 =sc.textFile(文件路径) |
数据计算
在计算前,需要给spark提供Python解释器的地址
1 | import os |
map方法(无额外功能)
可以将RDD的每个数据交给指定的函数处理,并返回新的RDD
1 | def AAA(A): |
flatMap方法(去嵌套)
有除去嵌套功能的Map方法
1 | RDD1 = sc.parallelize(["1,2,3","4,5,6"]) |
reduceByKey方法(分组聚合)
对KV类型(二元元组)的key进行分类,然后对V进行操作,然后返回V继续执行操作最后完成key1的操作返回(K,V),再完成key2…
1 | RDD1 = sc.parallelize([("男",99),("男",88),("女",99),("女",69),("女",100)]) |
注意:方法接收的函数只负责聚合,分组由方法自动完成
filter方法(筛选)
筛选数据,如果返回值是Ture,则保存
1 | RDD1 = sc.parallelize([1,2,3,4,5,6]) |
distinct方法(去重)
无需传入函数
1 | RDD1 = sc.parallelize([1,2,2,3,4,5,6,2,3,4,6,5,9]) |
sortBy方法(排序)
语法:sortBy(函数,ascending=True/Flase,numPartitions=1)
函数的返回值是排序的关键,ascending=True(升序),Flase(降序),numPartitions=1表示一个分区(不用管)
1 | RDD1 = sc.parallelize([(3,"a","一号"),(2,"b","二号"),(1,"c","三号")]) |
数据输出
输出为Python容器
**collect()**方法可以将RDD转化为list(列表)
1 | RDD2.collect() |
reduce方法对RDD按照传入的逻辑进行聚合,返回值和传入的参数一致
1 | RDD1 = sc.parallelize([1,2,3,4,5,6]) |
take方法对RDD取前N个元素,组成list返回
1 | RDD1 = sc.parallelize([1,2,3,4,5,6]) |
count方法对RDD进行计算有多少条数据,返回数字
1 | RDD1 = sc.parallelize([1,2,3,4,5,6]) |
输出为文件
下载
- 解压到任意文件夹
下载链接 提取码: iaee
- 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- hadoop.dll,并放入:C:/Windows/System32 文件夹内
指向HADOOP路径
1 | os.environ['HADOOP_HOME']="D:/C++笔记/hadoop-3.0.0" |
将RDD分区设置为1
1 | 全局设置 |
输出到文件夹saveAsTextFile(“路径”)
路径不可已存在
1 | RDD1.saveAsTextFile("D:/C++笔记/python/123") |
综合案例
1 | 00:00:00 2982199073774412 传智播客 8 3 http://www.itcast.cn |
获取哪个小时搜索数量是最多的,前3
1 | #导入包 |
将时间和用户id数据转化为json
1 | RDD1 = sc.textFile("search_log.txt") |
进阶
闭包
在程序中,如果设置了全局变量,那么全局变量很容易被别人修改
通过在外面嵌套一个函数,让全局变量作为外函数的参数参与内函数的使用则称为闭包
我们可以将外函数返回内函数赋给变量,以变量的形式使用内函数,那么外函数的参数则不容易被修改
1 | def AAA(name): |
如果在闭包中,需要在内函数中修改外函数的参数:在内函数:nonlocal 参数名
1 | def ATM(A=0): |
注意:如果使用闭包的话,那么内函数会持续引用外函数的值,会导致这部分的内存一直不被释放
装饰器
如果我们要为一个函数添加新的功能,但是不去破坏函数本身,那么我可以使用装饰器,装饰器本质上也是闭包
1 | def CCC(C): |
方法2
在原来函数前面@闭包函数,本质上也是传入闭包函数,但是可以直接使用原来的函数名调用新的函数体
1 | def CCC(C): |
设计模式
单例模式
在很多时候,我们使用工具类的时候,往往是会不停的实例对象,这样会占用很多资源,这个时候我们可以使用单例模式,让类只有一个实例,所有的访问点都是访问这个实例对象,而不是创建新的对象
实现:
在创建类的时候,我们可以直接在类的文件中将类实例一个对象
1 | ABC.py |
在我们要使用这个类的时候,可以直接导入这个类的对象,用变量接收,那么这个变量就可以调用对象的一切功能
1 | from ABC import aaa |
工厂模式
如果我们需要大量创建对象的时候,我们可以使用工厂模式,创建一个工厂的类,在类里面统一管理实例对象
有统一的接口方便维护,当类的名称需要改变的时候,只需要修改工厂的接口即可
1 | class AAA : |
多线程编程
在电脑中,程序的运行在系统中称之为进程,一个进程中有多个线程执行具体的任务
进程之间内容是相互隔离的,而线程之间内容是相互共享的
系统相当于一栋写字楼,进程相当于在写字楼的公司,每个公司之间是隔离开在不同的楼层的,线程相当于公司里面的员工,每个员工有具体的工作,员工在公司里面是共享信息和移动的
通过threading可以实现多线程编程
导入threading包
1 | import threading |
实例对象
thread_obj = threading.Thread([group [, target [, name [, args [, kwargs]]]]])
group:暂时无用,未来功能的预留参数
target:执行的目标任务名
args:以元组的方式给执行任务传参
kwargs:以字典方式给执行任务传参
name:线程名,一般不用设置
执行线程
thread_obj.start()
1 | import threading |
网络编程
Socket是进程之间通讯的工具,进程之间需要进行网络通讯需要通过socket
两个进程之间通讯必须要有服务端和客户端
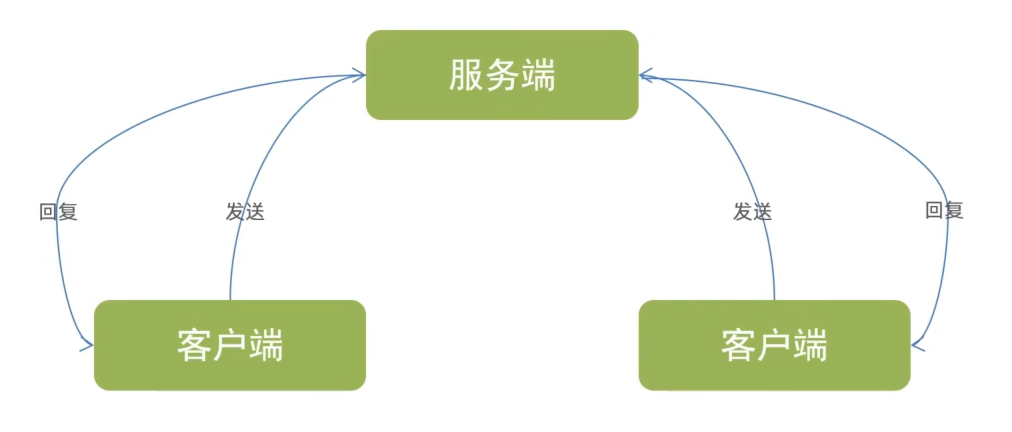
服务端
等待其他进程的连接,接收发来的信息,可以回复信息
1.导入包
1 | import socket |
2.创建Socket对象
1 | socket_server =socket.socket() |
3.绑定ip地址和端口
localhost代表本机
1 | socket_server.bind(("localhost",8888)) |
4.监听端口连接的数量
1 | socket server.listen(1) |
5.监听端口的信息
1 | conn,address=socket_server.accept() |
6.获取客户端发来的信息
1 | print(f"接收到了客户端的链接,客户端的信息是:{address}") |
7.处理客户端发来的信息
要使用客户端和服务端的本次链接对象,而非socket_server对象
1 | data:str =conn.recv(1024).decode("UTF-8") |
8.发送回复消息
1 | msg = input("请输入你要和客户端回复的消息:").encode("UTF-8") #encode可以将字符串编码为字节数组对象 |
9.关闭链接
1 | conn.close() |
客户端
主动连接服务端,可以发送信息,可以接收信息
1.导入包及创建对象
1 | import socket |
2.连接到服务端
1 | socket_client.connect(("localhost",8888)) |
3.发送消息
1 | socket_client.send("你好呀".encode("UTF-8")) |
4.接收返回消息
1 | recv_data =socket client.recv(1024)#1024是缓冲区的大小,一般1024即可。同样recv方法是阻塞的 |
5.关闭链接
1 | socket_client.close() |
区别
服务端用于可以接收多个客户端的信息,所以需要创建不同的连接对象,通过连接对象和客户端进行通讯
客户端由于只和服务端进行通讯,所以只用创建一个本体对象即可
正则表达式(基础匹配)
正则表达式就是规则匹配表达式,利用正则表达式指定规则进行检索和修改字符串
例如:利用正则表达式检索电子邮箱是否符合规则
Python正则表达式,使用re模块,并基于re模块中三个基础方法来做正则匹配
分别是:match、search、findall 三个基础方法
match
语法:re.match(匹配规则,被匹配字符串)
从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空
1 | import re |
search
语法:search(匹配规则,被匹配字符串)
搜索整个字符串,找出匹配的。从前向后,找到第一个后就停止,不会继续向后
1 | import re |
findall
语法:findall(匹配规则,被匹配字符串)
匹配整个字符串,找出全部匹配项
1 | import re |
正则表达式(元字符匹配)
单字符匹配
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n),**\ .**匹配点本身 |
| [ ] | 匹配[]中列举的字符 |
| \d | 匹配数字 0-9 |
| \D | 匹配非数字 |
| \s | 匹配空白,即空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符 a-z,A-Z,0-9,_ |
| \W | 匹配非单词字符 |
| \n | 匹配换行符 |
| \t | 匹配制表符 |
| [^] | 匹配不属于[]中列举的字符 |
| \ |
案例
字符串的r标记,表示当前字符串是原始字符串,即内部的转义字符无效而是普通字符
找出全部数字
1 | s="itheima1 @@python2!!666 ##itcast3" |
找出特殊字符
1 | s="itheima1 @@python2!!666 ##itcast3" |
找出全部英文字母
1 | s="itheima1 @@python2!!666 ##itcast3" |
数字匹配
| 字符 | 功能 |
|---|---|
| * | 匹配前一个规则的字符出现0至无数次 |
| + | 匹配前一个规则的字符出现1至无数次 |
| ? | 匹配前一个规则的字符出现0次或1次 |
| {m} | 匹配前一个规则的字符出现m次 |
| {m,} | 匹配前一个规则的字符出现最少m次 |
| {m,n} | 匹配前一个规则的字符出现m到n次 |
边界匹配
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词的边界 |
分组匹配
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| ( ) | 将括号中字符作为一个分组 |
贪婪匹配和惰性匹配
| 名称 | 字符 | 功能 |
|---|---|---|
| 贪婪匹配 | .* | 匹配尽可能多 |
| 惰性匹配 | .*? | 匹配尽可能少 |
1 | 我是大帅哥,我非常帅,大帅哥是我 |
案例
匹配账号,数字和字母组成,长度6-10
1 | import re |
匹配qq,5-11位,第一位不为0
1 | s="214566" |
匹配电子邮箱
只允许qq,163,gmait
(可以数字,字母,_,-,.)@邮箱.内容
1 | s="214566@qq.com" |
递归
递归就是函数调用自己
注意:递归必须要有结束条件
例如:一个获取文件夹的所以文件的函数
1 | import os |
注意:
递归值要从内到外层层返回
完结撒花
11月16日至12月8日,历时22天











